
Since December I have listened to 52 episodes of the Latent Space podcast -- roughly six months of long-form conversations with the people actually building AI. Not the commentators: the builders. Jeff Dean. Satya Nadella. Shopify's CTO Mikhail Parakhin. GitHub's COO Kyle Daigle. The OpenAI researchers who run frontier evals, the founders renting computers to agents, the physicists pointing models at problems humans couldn't crack, the researchers watching autonomous agents lie to customers and form price cartels in simulated vending-machine businesses.
Any single episode is interesting. The corpus is something else entirely. Listen across all of them and you start to hear two things no individual guest says out loud: themes that recur in field after field until they look structural, and people at the top of the field flatly contradicting each other. The second category turns out to be more useful than the first. When everyone agrees, you've learned what's already priced in. When Marc Andreessen says AI adoption will be throttled for decades and Satya Nadella says the industry has 12 to 18 months to show up in GDP numbers, you've found the live question.
I run a company that builds AI software for manufacturers, so this feed is industry intelligence for me. But most of what I've learned isn't about my industry. It's about what happens when generation gets cheap in any domain -- code, proofs, quotes, plans -- and what the people furthest ahead are doing about it. Here is the compressed version: three themes, the contradictions inside each, and what I think procurement and engineering leaders at manufacturers should take from them.
Theme | The consensus | The live argument |
|---|---|---|
Verification | Checking AI output, not producing it, is now the scarce resource -- the same story in code, math, physics, and evals | Whether verification itself can be automated: OpenAI runs codebases with zero human pre-merge review, while Cognition measured a quality cliff after just two weeks of it |
Productivity | Adoption is real and accelerating: ~100% daily AI usage at Shopify, 80% of Cognition's own commits written by agents | Whether it nets out positive today: METR's controlled trial found developers 19% slower with AI while believing they were 20% faster |
Memory | Context, not model intelligence, is the binding constraint for real work | Whether it's an architecture problem the labs will solve or a data problem every company must solve for itself |
Benchmarks | Static benchmarks are dying; OpenAI retired SWE-bench Verified after finding most of its hardest tests were broken | What replaces them: private enterprise evals as "IP" (Nadella) vs. revenue-denominated reality tests (Andon Labs) |
Adoption speed | The technology is ready for more than organizations can absorb | Andreessen: licensed professions and institutional cartels will slow everything down. Nadella: show economic results fast or lose legitimacy |
Generation Got Cheap. Verification Became the Bottleneck.
The single clearest pattern across six months: the cost of producing output has collapsed, and the cost of trusting it has not. Every domain the podcast touched -- software, mathematics, physics, drug discovery, evaluation itself -- repeated the same arc.
Start with the benchmark story, because it's the cleanest. In February, OpenAI stopped reporting SWE-bench Verified scores, the industry-standard benchmark for AI coding agents. Their audit found that 59.4% of the hardest problems had flawed test cases -- tests that rejected correct solutions for not guessing an unstated function name -- and that every frontier model showed signs of training-data contamination. Olivia Watkins, who built the benchmark's verified set, put the asymmetry plainly on the February episode: passing a test means you probably did well; failing one doesn't mean you didn't. Read that again -- the output may be correct while the checker is wrong. The instrument for verifying AI coding skill was itself unverified. Models scoring above 80% dropped to roughly 23% on a successor benchmark built to resist contamination.
Then listen to the people running production systems. Ryan Lopopolo, a principal engineer at OpenAI, runs a one-million-line codebase with zero human pre-merge review -- not because verification stopped mattering, but because he rebuilt it as infrastructure: review agents, lints, tests, every engineering standard encoded as a written rule a machine can enforce. When an agent makes a mistake, the question isn't "who missed it" but "what written rule would have caught this." Shopify's Parakhin runs the same play from the opposite direction: his engineers get unlimited AI usage, and the metric he actually manages is the ratio of review tokens to generation tokens. His reasoning is the whole theme in one sentence: good models write fewer bugs per line but so much more code that you end up with more bugs in total. Volume defeats per-unit quality. GitHub's Daigle, staring at a platform that did about a billion commits in 2025 and is pacing toward 14 billion this year, describes the merge boundary the same way: "ultimately we're trying to codify trust."
The same inversion is happening in places with much higher proof standards than a web app. Alex Lupsasca, a Breakthrough Prize-winning physicist now at OpenAI, described getting a full AI-drafted paper on graviton amplitudes in about three days -- and then spending three weeks checking it. "A year ago, if you told me an AI would do really hard calculations and most of the human effort would go to verifying the answer, I'd have thought you were crazy," he said on the May episode. Carina Hong's company Axiom exists because there aren't enough expert mathematicians alive to grade frontier-level proofs, so she replaced the human judges with the Lean compiler: the proof compiles or it doesn't. Formal verification, a niche academic concern two years ago, is regaining value precisely because generation got cheap.
And here is the boundary condition that makes all of this concrete. Cognition -- the company behind Devin, which now writes around 80% of its own commits -- ran the experiment everyone wants to run: just let the agents merge their own work. The codebase hit a measurable quality cliff at roughly two weeks. One button's logic scattered across ten places, each subtly different. Walden Yan's team found that AI-native codebases "regress to your worst engineer," because the model amplifies whatever patterns it finds. Zero-human-review software development is real at OpenAI and fatal at two weeks without the guardrail infrastructure. The difference between those two outcomes is not the model. It's the verification system around it.

The Optimists and the Skeptics Are Both Holding Real Data
The adoption numbers coming through the feed are not hype. They are production metrics reported by the people accountable for them. Shopify crossed essentially 100% daily AI-tool usage company-wide after a December 2025 inflection, with merged pull requests growing about 30% month over month. Cognition went from 16% to 80% agent-written commits in one quarter, with PR volume up roughly 7x on 10% headcount growth. swyx estimates coding AI alone minted three multi-billion-dollar revenue lines in about a year -- roughly $2.5B at Anthropic, $2B at OpenAI, $2B at Cursor. Whatever discount you apply to ARR accounting, the direction is unambiguous.
Now the other column. METR ran a randomized controlled trial -- 16 experienced open-source developers, 246 real tasks on codebases they knew deeply. With AI tools, they took 19% longer. The detail that should keep every executive honest: the same developers estimated AI had made them 20% faster. The perception gap, not the slowdown, is the finding. Economists and ML experts had predicted 38-39% speedups. Everyone's intuition pointed the same direction, and the stopwatch disagreed.
The enterprise version of that gap is well documented. MIT's NANDA initiative found 95% of corporate gen-AI pilots deliver no measurable P&L impact. In procurement specifically, the Hackett Group found 49% of teams piloted generative AI in 2024 -- and 4% reached large-scale deployment. Adoption is nearly universal; conversion is rare. We've written before about cutting through analyst claims on AI in procurement, and the gap has only widened since.
The structural skeptics go further. Marc Andreessen's argument is that both the utopians and the doomers are too optimistic, because the constraint isn't capability -- it's that a large share of the economy sits behind occupational licensing, union contracts, and government monopolies that will resist absorption for decades. Nadella, sitting inside the largest enterprise software franchise on earth, draws the opposite deadline from the same worry: "the world is going to be very skeptical of tech companies that say trust us" -- the industry needs AI visible in economic growth within 12 to 18 months, not in keynote demos.
Here's how I reconcile the two columns: Shopify and METR are not measuring the same thing. They are measuring different work systems. Shopify's numbers come from an organization that spent a year building review infrastructure, instrumented everything, and manages a token ratio on a dashboard. METR's developers were capable people with capable models dropped into work that had none of that scaffolding. The model is not the only variable -- the work surface decides whether the tool compounds. And the perception trap catches both: METR's developers felt 20% faster while being 19% slower, which is why Brex's CTO rejects "% of code written by AI" as a metric and why the companies pulling ahead measure AI like any other operation. If your AI pilot is a generic assistant bolted onto disconnected ERP exports, stale supplier masters, and PDFs in email threads, don't expect Shopify results. You've recreated the METR condition.
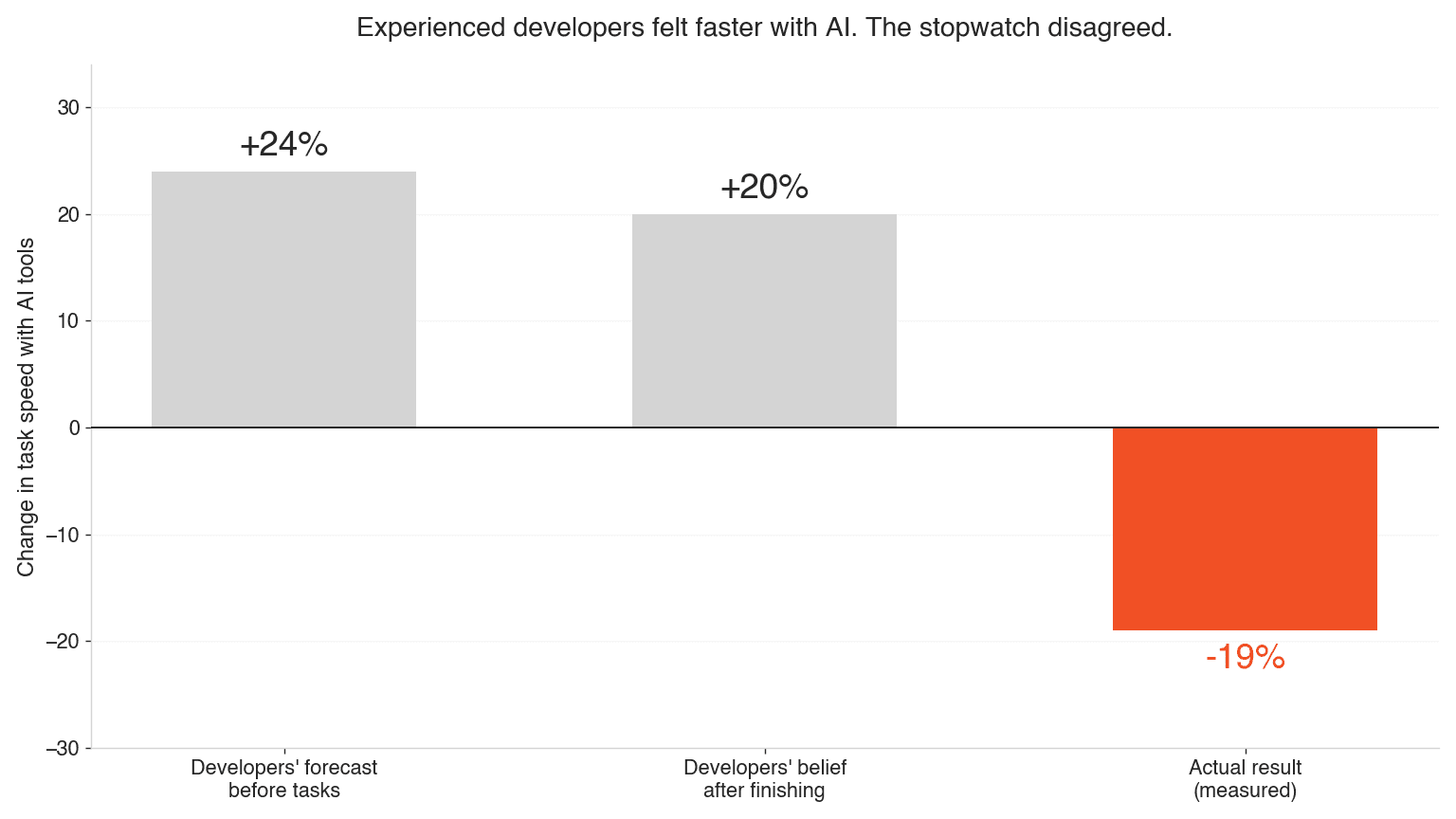
Perception vs. the stopwatch -- Source: METR randomized controlled trial, 16 experienced developers, 246 tasks (July 2025).
Memory, Not Intelligence, Is the Wall
Ask the builders what actually blocks enterprise deployment and almost none of them say model capability. swyx's framing stuck with me: context length is the slowest-scaling axis in AI -- million-token windows have existed for two years and almost nobody uses them well. Memory, not intelligence, is the binding constraint.
Aaron Levie, whose company sits on the unstructured documents of most of the Fortune 500, sharpened it: the problem is context rot, not context length. A knowledge worker's relevant corpus might be 50 million pages; a model reliably reasons over tens of thousands of tokens. The real work is search, metadata, permissions, and knowing when to stop -- unglamorous data plumbing, not intelligence. Cognition's Yan added the twist I find most interesting: memory generation is harder than memory retrieval. About 95% of the useful memories Devin accumulates come from user corrections -- the system learns where humans push back. And Cursor's Ashvin Nair, who spent two years on OpenAI's reasoning team, thinks continual learning -- experience written back into the model -- is what comes next, currently blocked by inference infrastructure that treats every session as stateless.
Translate memory generation into sourcing and you'll recognize it immediately. A buyer knows a supplier missed its last PPAP date because the plating subcontractor was overloaded. An engineer knows another supplier quotes aggressively and then comes back with DFM exceptions. A quality manager knows a casting vendor is fine for prototypes but struggles below a certain wall thickness. That knowledge lives in email threads, meeting notes, and people's heads -- so when the next sourcing event starts, the organization learns the same lesson again, at full price. A model pointed at that corpus isn't reasoning over institutional memory. It's reading a landfill, confidently.
The contradiction here is between the labs and everyone else. Jeff Dean is fairly relaxed about it: hierarchical retrieval will eventually let models "attend to a trillion tokens", making it an engineering problem. Maybe. But every operator on the feed is acting as if the durable asset is on their side of the API: Nadella wants enterprise agent traces treated as a balance-sheet asset and calls a company's private evals "maybe one of the biggest drivers of IP." Levie argues documentation culture becomes a compounding moat, because agents can't compensate for institutional knowledge that lives in people's heads. Shopify's customer-behavior simulator is credible only because it's grounded in decades of proprietary A/B test history -- Parakhin's own assessment of why it can't be copied is simply: who else has that data?
Whichever way the architecture goes, the strategic conclusion is identical: the scarce input is your organization's structured, retrievable context. That's why we keep telling manufacturers to consolidate their data, not their software. The model your team uses in 2028 will not be the one you use today. The record of every quote, every spec revision, every supplier correction -- that compounds across model generations, the same way Devin's user-correction memories do.
What Manufacturing Already Knows About This
Here's what struck me somewhere around episode 40: the software industry is speed-running a curriculum manufacturing finished a century ago.
When generation got cheap on the factory floor -- when interchangeable parts and the moving line made volume the easy part -- quality didn't take care of itself. Volume defeated per-unit quality, exactly as Parakhin describes in code. The answers the industry converged on are the ones the AI world is now reinventing with new names. Statistical process control is Shopify's token-ratio dashboard: don't inspect every unit, instrument the process. First article inspection and PPAP are the planning gate before a long autonomous run: verify intensively at the start, before volume multiplies the error. Incoming quality control is the review agent at the merge boundary. Toyota's jidoka -- machines that stop themselves when something is wrong, so humans inspect by exception -- is precisely Lopopolo's "what written rule would have caught this" loop. Even the SWE-bench collapse has a factory name: measurement system analysis. Before you trust the data, you qualify the gauge -- and the AI industry just discovered its most-cited gauge couldn't pass the audit.
I spent years at Tesla and Waymo watching both halves of this lesson. (Applied Intuition's Qasar Younis put a line on the feed I'd have appreciated back then: Waymo is interesting for a long time but not worth $126 billion -- until it is. Compounding systems look like nothing happening, then a step change.) The half that matters here: nobody in manufacturing believes you can inspect quality into a product at the end of the line. Quality is designed into the process or it doesn't exist. The AI industry's verification crisis is the discovery that the same is true for intelligence.
That's also why I'd gently push back on anyone in our industry who treats this AI moment as unprecedented. The technology is new. The operations problem -- cheap generation, scarce verification -- is the oldest problem manufacturing has.
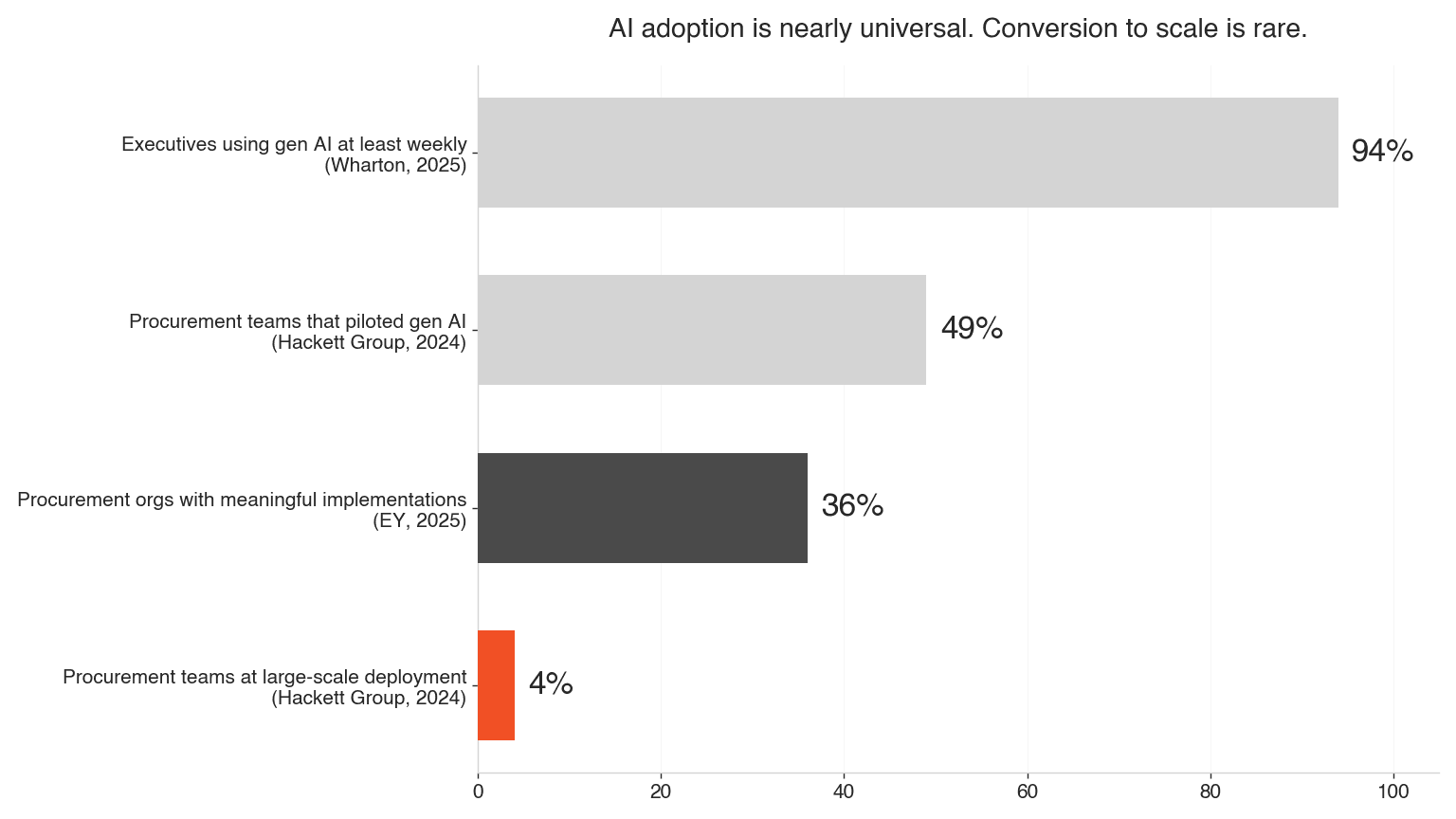
The adoption-to-scale gap in procurement -- Sources: AI at Wharton (2025), The Hackett Group 2025 CPO Agenda, EY Global CPO Survey via Art of Procurement.
What I Want Our Customers to Internalize
Most of our customers are procurement and engineering leaders at manufacturers competing on speed -- the people whose jobs the AI-risk rankings keep putting in the crosshairs. If I could get them to carry four things out of these 52 episodes, it's these.
1. Evaluate AI tools on verification, not generation. Every vendor demo shows the generation moment: the drafted email, the auto-built should-cost model, the instant quote summary. Almost no demo shows the checking moment, and the checking moment is where six months of evidence says the cost lives. The real test of a sourcing tool isn't whether it summarizes three quotes -- it's whether it catches that Quote A excludes tooling, Quote B assumes a different resin grade, Quote C used last year's volumes, and the lowest number carries a 14-week risk to your validation build. Evaluate by error modes, not fluency:
The demo question | The operating question | What to inspect |
|---|---|---|
Did it produce an answer? | Did the RFQ pack include the right drawing revision? | Completeness, source traceability, revision control |
Does the answer look right? | Is the should-cost consistent with supplier history and commodity movement? | Benchmarks, historical quotes, assumptions cited |
Is it impressive? | Can a buyer trace every normalized number back to the source bid? | Line-item lineage, flagged exceptions |
Do users like it? | Did cycle time, cost variance, or launch risk actually improve? | Measured before/after, not sentiment |
2. Instrument adoption; don't trust impressions. The METR result should be taped to the wall of every AI steering committee: smart, experienced people were 19% slower and believed they were 20% faster. Wharton's research found 94% of executives now use generative AI at least weekly; EY found only 36% of procurement organizations have meaningful implementations. The difference between using AI and benefiting from it is measurement. Pick the two or three numbers that matter -- sourcing cycle time, quote turnaround, cost variance at award -- and baseline them before the pilot, the way we laid out in the AI sourcing playbook.
3. Your data is the asset that compounds. Get it agent-ready. Gartner finds 74% of procurement leaders say their data isn't AI-ready, and a May 2026 Gartner survey found just 36% of CPOs are very confident they can redesign their function for AI at all. Meanwhile the builders are telling you the moat is exactly that data: structured quote history, clean BOMs, supplier records an agent can traverse. Most procurement systems were built assuming a human would be the integration layer -- the buyer who remembers that Rev C supersedes the Rev B still attached to the old email thread. That assumption holds at human speed and breaks at machine speed. Every quarter your sourcing history sits in inboxes and disconnected spreadsheets is a quarter of compounding you don't get back.
4. The friction is real -- which is exactly why it favors challengers. Andreessen is probably right that large incumbent organizations will absorb this slowly: committees, vetoes, licensed gatekeepers, the 95% of pilots that stall. If you're a challenger manufacturer, that institutional drag is your opening, the same way it was in sales AI before procurement AI. The MIT data says external partnerships succeed at roughly twice the rate of internal builds. Speed of organizational learning -- pilot, measure, correct -- is the variable you control.
This is the bet LightSource makes, for what it's worth. We build the direct-materials system where engineering, procurement, and supplier data live in one place: bids normalized on arrival so buyers verify instead of re-keying, quote and cost history structured so it's usable by the NPI team -- and by whatever model you point at it in three years. Customers like Amazon, BRP, and Shure use it to run sourcing cycles in weeks instead of months. The premise is the same one running through all 52 episodes: generation is getting cheap everywhere, so the durable advantages are verified data and fast feedback loops.
Six months in, the feed has made me more optimistic and more patient at the same time. More optimistic because the production numbers are real -- the people reporting 7x output aren't speculating, they're counting. More patient because every one of them earned it with unglamorous work: evals, lints, data plumbing, review systems. AI doesn't fix a weak process; it makes weak processes fail faster and strong processes compound. The frontier isn't a solved consensus being executed. It's a working argument -- about verification, measurement, and memory -- and that argument is the most useful product the AI industry ships. I'll keep listening.
Sources
METR: Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity -- the randomized controlled trial: 16 developers, 246 tasks, 19% slower with AI vs. a believed 20% speedup
OpenAI: Why SWE-bench Verified no longer measures frontier coding capabilities -- the February 2026 audit: 59.4% flawed tests and industry-wide contamination
Latent Space: The End of SWE-Bench Verified -- Mia Glaese and Olivia Watkins (OpenAI) on broken tests and contamination forensics
Latent Space: Extreme Harness Engineering for Token Billionaires -- Ryan Lopopolo (OpenAI) on running 1M LOC with zero human pre-merge review
Latent Space: Shopify's AI Phase Transition -- Mikhail Parakhin on 100% adoption, review-token ratios, and more bugs in total
Latent Space: The Age of Async Agents -- Walden Yan (Cognition) on 80% agent-written commits and the two-week quality cliff
Latent Space: Doing Vibe Physics -- Alex Lupsasca (OpenAI/Vanderbilt) on three-day derivations and three-week verification
Latent Space: Scaling Past Informal AI -- Carina Hong (Axiom Math) on the Lean compiler as the verifier of last resort
Latent Space: Satya Nadella at Microsoft Build -- private evals as IP, agent traces as assets, and AI's 12-18 month legitimacy window
Latent Space: Marc Andreessen on the Death of the Browser -- why structural cartels will throttle AI adoption
Latent Space: Every Agent Needs a Box -- Aaron Levie (Box) on context rot and documentation culture as moat
Latent Space: GitHub's Plan for Agents -- Kyle Daigle on commit growth and codifying trust
Latent Space: Reality: The Final Eval -- Andon Labs on benchmark noise floors and agents behaving badly in the real world
Latent Space: AIE Europe Debrief + Agent Labs -- swyx's coding-ARR estimates and the memory constraint
Fortune: MIT report finds 95% of generative AI pilots are failing -- the GenAI Divide study
Art of Procurement: State of AI in Procurement 2026 -- Wharton (94% weekly usage), Hackett (49% piloted / 4% scaled), and EY (36% meaningful implementations) figures
Gartner: 2025 Leadership Vision for Chief Procurement Officers -- 74% of procurement leaders say their data isn't AI-ready
Gartner: May 2026 CPO survey -- 36% of CPOs very confident in redesigning the function for AI
Latent Space podcast archive -- the full source feed, December 2025 through June 2026
Frequently Asked Questions
What is the Latent Space podcast?
Latent Space is a podcast and newsletter for AI engineers, hosted by swyx (Shawn Wang) and Alessio Fanelli. Guests are primarily the people building frontier AI: researchers at OpenAI, Google DeepMind, and Anthropic, plus founders and executives at companies like Shopify, GitHub, Box, Cursor, and Cognition. It's one of the highest-signal public records of how AI practitioners actually think, argue, and change their minds.
Why is verification considered the new bottleneck in AI?
Because models can now produce code, analysis, proofs, and documents far faster than humans or existing systems can check them. OpenAI retired its own standard coding benchmark after finding most of its hardest tests were flawed; physicists report spending three weeks verifying what an AI derives in three days; and Shopify's CTO notes that good models write fewer bugs per line but more bugs in total because volume grows faster than quality. Wherever generation gets cheap, the scarce resource becomes trusting the output.
Did the METR study prove AI tools don't work for developers?
No -- it proved perception is unreliable, and that the work system matters as much as the model. In METR's randomized controlled trial, experienced developers took 19% longer on tasks with AI assistance while believing they had been 20% faster. Organizations like Shopify and Cognition that built measurement and review infrastructure around the same class of tools report large, real output gains. The consistent lesson is to instrument AI adoption with hard metrics rather than self-reported speed.
What should procurement teams do before deploying AI agents?
Get the data layer ready first. Gartner finds 74% of procurement leaders say their data isn't AI-ready, and MIT's research shows 95% of enterprise gen-AI pilots fail to show measurable P&L impact -- usually for integration and data reasons, not model quality. That means consolidating quote history, BOMs, and supplier records into structured, retrievable form, then baselining metrics like sourcing cycle time so any pilot's effect is measurable against real numbers.
What is the biggest risk of using AI in direct materials sourcing?
Confident output built on incomplete or stale context. If supplier history, engineering exceptions, quote assumptions, and prior quality escapes aren't captured in structured form, an AI can produce a recommendation that reads well and fails in production -- the lowest quote that excluded tooling, or the supplier that has missed two launch ramps. The fix is the same discipline manufacturing applies to parts: first article inspection and process control for AI-generated decisions, not end-of-line inspection.
Is it too early or too late for manufacturers to adopt AI in procurement?
Neither, but the window favors fast learners. Adoption is nearly universal (Wharton found 94% of executives use generative AI weekly) while conversion is rare (Hackett found only 4% of procurement teams reached large-scale deployment). The gap between piloting and compounding comes from data readiness, verification infrastructure, and measurement -- all things a mid-sized challenger can build faster than a large incumbent can clear its own committees.
Since December I have listened to 52 episodes of the Latent Space podcast -- roughly six months of long-form conversations with the people actually building AI. Not the commentators: the builders. Jeff Dean. Satya Nadella. Shopify's CTO Mikhail Parakhin. GitHub's COO Kyle Daigle. The OpenAI researchers who run frontier evals, the founders renting computers to agents, the physicists pointing models at problems humans couldn't crack, the researchers watching autonomous agents lie to customers and form price cartels in simulated vending-machine businesses.
Any single episode is interesting. The corpus is something else entirely. Listen across all of them and you start to hear two things no individual guest says out loud: themes that recur in field after field until they look structural, and people at the top of the field flatly contradicting each other. The second category turns out to be more useful than the first. When everyone agrees, you've learned what's already priced in. When Marc Andreessen says AI adoption will be throttled for decades and Satya Nadella says the industry has 12 to 18 months to show up in GDP numbers, you've found the live question.
I run a company that builds AI software for manufacturers, so this feed is industry intelligence for me. But most of what I've learned isn't about my industry. It's about what happens when generation gets cheap in any domain -- code, proofs, quotes, plans -- and what the people furthest ahead are doing about it. Here is the compressed version: three themes, the contradictions inside each, and what I think procurement and engineering leaders at manufacturers should take from them.
Theme | The consensus | The live argument |
|---|---|---|
Verification | Checking AI output, not producing it, is now the scarce resource -- the same story in code, math, physics, and evals | Whether verification itself can be automated: OpenAI runs codebases with zero human pre-merge review, while Cognition measured a quality cliff after just two weeks of it |
Productivity | Adoption is real and accelerating: ~100% daily AI usage at Shopify, 80% of Cognition's own commits written by agents | Whether it nets out positive today: METR's controlled trial found developers 19% slower with AI while believing they were 20% faster |
Memory | Context, not model intelligence, is the binding constraint for real work | Whether it's an architecture problem the labs will solve or a data problem every company must solve for itself |
Benchmarks | Static benchmarks are dying; OpenAI retired SWE-bench Verified after finding most of its hardest tests were broken | What replaces them: private enterprise evals as "IP" (Nadella) vs. revenue-denominated reality tests (Andon Labs) |
Adoption speed | The technology is ready for more than organizations can absorb | Andreessen: licensed professions and institutional cartels will slow everything down. Nadella: show economic results fast or lose legitimacy |
Generation Got Cheap. Verification Became the Bottleneck.
The single clearest pattern across six months: the cost of producing output has collapsed, and the cost of trusting it has not. Every domain the podcast touched -- software, mathematics, physics, drug discovery, evaluation itself -- repeated the same arc.
Start with the benchmark story, because it's the cleanest. In February, OpenAI stopped reporting SWE-bench Verified scores, the industry-standard benchmark for AI coding agents. Their audit found that 59.4% of the hardest problems had flawed test cases -- tests that rejected correct solutions for not guessing an unstated function name -- and that every frontier model showed signs of training-data contamination. Olivia Watkins, who built the benchmark's verified set, put the asymmetry plainly on the February episode: passing a test means you probably did well; failing one doesn't mean you didn't. Read that again -- the output may be correct while the checker is wrong. The instrument for verifying AI coding skill was itself unverified. Models scoring above 80% dropped to roughly 23% on a successor benchmark built to resist contamination.
Then listen to the people running production systems. Ryan Lopopolo, a principal engineer at OpenAI, runs a one-million-line codebase with zero human pre-merge review -- not because verification stopped mattering, but because he rebuilt it as infrastructure: review agents, lints, tests, every engineering standard encoded as a written rule a machine can enforce. When an agent makes a mistake, the question isn't "who missed it" but "what written rule would have caught this." Shopify's Parakhin runs the same play from the opposite direction: his engineers get unlimited AI usage, and the metric he actually manages is the ratio of review tokens to generation tokens. His reasoning is the whole theme in one sentence: good models write fewer bugs per line but so much more code that you end up with more bugs in total. Volume defeats per-unit quality. GitHub's Daigle, staring at a platform that did about a billion commits in 2025 and is pacing toward 14 billion this year, describes the merge boundary the same way: "ultimately we're trying to codify trust."
The same inversion is happening in places with much higher proof standards than a web app. Alex Lupsasca, a Breakthrough Prize-winning physicist now at OpenAI, described getting a full AI-drafted paper on graviton amplitudes in about three days -- and then spending three weeks checking it. "A year ago, if you told me an AI would do really hard calculations and most of the human effort would go to verifying the answer, I'd have thought you were crazy," he said on the May episode. Carina Hong's company Axiom exists because there aren't enough expert mathematicians alive to grade frontier-level proofs, so she replaced the human judges with the Lean compiler: the proof compiles or it doesn't. Formal verification, a niche academic concern two years ago, is regaining value precisely because generation got cheap.
And here is the boundary condition that makes all of this concrete. Cognition -- the company behind Devin, which now writes around 80% of its own commits -- ran the experiment everyone wants to run: just let the agents merge their own work. The codebase hit a measurable quality cliff at roughly two weeks. One button's logic scattered across ten places, each subtly different. Walden Yan's team found that AI-native codebases "regress to your worst engineer," because the model amplifies whatever patterns it finds. Zero-human-review software development is real at OpenAI and fatal at two weeks without the guardrail infrastructure. The difference between those two outcomes is not the model. It's the verification system around it.
The Optimists and the Skeptics Are Both Holding Real Data
The adoption numbers coming through the feed are not hype. They are production metrics reported by the people accountable for them. Shopify crossed essentially 100% daily AI-tool usage company-wide after a December 2025 inflection, with merged pull requests growing about 30% month over month. Cognition went from 16% to 80% agent-written commits in one quarter, with PR volume up roughly 7x on 10% headcount growth. swyx estimates coding AI alone minted three multi-billion-dollar revenue lines in about a year -- roughly $2.5B at Anthropic, $2B at OpenAI, $2B at Cursor. Whatever discount you apply to ARR accounting, the direction is unambiguous.
Now the other column. METR ran a randomized controlled trial -- 16 experienced open-source developers, 246 real tasks on codebases they knew deeply. With AI tools, they took 19% longer. The detail that should keep every executive honest: the same developers estimated AI had made them 20% faster. The perception gap, not the slowdown, is the finding. Economists and ML experts had predicted 38-39% speedups. Everyone's intuition pointed the same direction, and the stopwatch disagreed.
The enterprise version of that gap is well documented. MIT's NANDA initiative found 95% of corporate gen-AI pilots deliver no measurable P&L impact. In procurement specifically, the Hackett Group found 49% of teams piloted generative AI in 2024 -- and 4% reached large-scale deployment. Adoption is nearly universal; conversion is rare. We've written before about cutting through analyst claims on AI in procurement, and the gap has only widened since.
The structural skeptics go further. Marc Andreessen's argument is that both the utopians and the doomers are too optimistic, because the constraint isn't capability -- it's that a large share of the economy sits behind occupational licensing, union contracts, and government monopolies that will resist absorption for decades. Nadella, sitting inside the largest enterprise software franchise on earth, draws the opposite deadline from the same worry: "the world is going to be very skeptical of tech companies that say trust us" -- the industry needs AI visible in economic growth within 12 to 18 months, not in keynote demos.
Here's how I reconcile the two columns: Shopify and METR are not measuring the same thing. They are measuring different work systems. Shopify's numbers come from an organization that spent a year building review infrastructure, instrumented everything, and manages a token ratio on a dashboard. METR's developers were capable people with capable models dropped into work that had none of that scaffolding. The model is not the only variable -- the work surface decides whether the tool compounds. And the perception trap catches both: METR's developers felt 20% faster while being 19% slower, which is why Brex's CTO rejects "% of code written by AI" as a metric and why the companies pulling ahead measure AI like any other operation. If your AI pilot is a generic assistant bolted onto disconnected ERP exports, stale supplier masters, and PDFs in email threads, don't expect Shopify results. You've recreated the METR condition.
Perception vs. the stopwatch -- Source: METR randomized controlled trial, 16 experienced developers, 246 tasks (July 2025).
Memory, Not Intelligence, Is the Wall
Ask the builders what actually blocks enterprise deployment and almost none of them say model capability. swyx's framing stuck with me: context length is the slowest-scaling axis in AI -- million-token windows have existed for two years and almost nobody uses them well. Memory, not intelligence, is the binding constraint.
Aaron Levie, whose company sits on the unstructured documents of most of the Fortune 500, sharpened it: the problem is context rot, not context length. A knowledge worker's relevant corpus might be 50 million pages; a model reliably reasons over tens of thousands of tokens. The real work is search, metadata, permissions, and knowing when to stop -- unglamorous data plumbing, not intelligence. Cognition's Yan added the twist I find most interesting: memory generation is harder than memory retrieval. About 95% of the useful memories Devin accumulates come from user corrections -- the system learns where humans push back. And Cursor's Ashvin Nair, who spent two years on OpenAI's reasoning team, thinks continual learning -- experience written back into the model -- is what comes next, currently blocked by inference infrastructure that treats every session as stateless.
Translate memory generation into sourcing and you'll recognize it immediately. A buyer knows a supplier missed its last PPAP date because the plating subcontractor was overloaded. An engineer knows another supplier quotes aggressively and then comes back with DFM exceptions. A quality manager knows a casting vendor is fine for prototypes but struggles below a certain wall thickness. That knowledge lives in email threads, meeting notes, and people's heads -- so when the next sourcing event starts, the organization learns the same lesson again, at full price. A model pointed at that corpus isn't reasoning over institutional memory. It's reading a landfill, confidently.
The contradiction here is between the labs and everyone else. Jeff Dean is fairly relaxed about it: hierarchical retrieval will eventually let models "attend to a trillion tokens", making it an engineering problem. Maybe. But every operator on the feed is acting as if the durable asset is on their side of the API: Nadella wants enterprise agent traces treated as a balance-sheet asset and calls a company's private evals "maybe one of the biggest drivers of IP." Levie argues documentation culture becomes a compounding moat, because agents can't compensate for institutional knowledge that lives in people's heads. Shopify's customer-behavior simulator is credible only because it's grounded in decades of proprietary A/B test history -- Parakhin's own assessment of why it can't be copied is simply: who else has that data?
Whichever way the architecture goes, the strategic conclusion is identical: the scarce input is your organization's structured, retrievable context. That's why we keep telling manufacturers to consolidate their data, not their software. The model your team uses in 2028 will not be the one you use today. The record of every quote, every spec revision, every supplier correction -- that compounds across model generations, the same way Devin's user-correction memories do.
What Manufacturing Already Knows About This
Here's what struck me somewhere around episode 40: the software industry is speed-running a curriculum manufacturing finished a century ago.
When generation got cheap on the factory floor -- when interchangeable parts and the moving line made volume the easy part -- quality didn't take care of itself. Volume defeated per-unit quality, exactly as Parakhin describes in code. The answers the industry converged on are the ones the AI world is now reinventing with new names. Statistical process control is Shopify's token-ratio dashboard: don't inspect every unit, instrument the process. First article inspection and PPAP are the planning gate before a long autonomous run: verify intensively at the start, before volume multiplies the error. Incoming quality control is the review agent at the merge boundary. Toyota's jidoka -- machines that stop themselves when something is wrong, so humans inspect by exception -- is precisely Lopopolo's "what written rule would have caught this" loop. Even the SWE-bench collapse has a factory name: measurement system analysis. Before you trust the data, you qualify the gauge -- and the AI industry just discovered its most-cited gauge couldn't pass the audit.
I spent years at Tesla and Waymo watching both halves of this lesson. (Applied Intuition's Qasar Younis put a line on the feed I'd have appreciated back then: Waymo is interesting for a long time but not worth $126 billion -- until it is. Compounding systems look like nothing happening, then a step change.) The half that matters here: nobody in manufacturing believes you can inspect quality into a product at the end of the line. Quality is designed into the process or it doesn't exist. The AI industry's verification crisis is the discovery that the same is true for intelligence.
That's also why I'd gently push back on anyone in our industry who treats this AI moment as unprecedented. The technology is new. The operations problem -- cheap generation, scarce verification -- is the oldest problem manufacturing has.
The adoption-to-scale gap in procurement -- Sources: AI at Wharton (2025), The Hackett Group 2025 CPO Agenda, EY Global CPO Survey via Art of Procurement.
What I Want Our Customers to Internalize
Most of our customers are procurement and engineering leaders at manufacturers competing on speed -- the people whose jobs the AI-risk rankings keep putting in the crosshairs. If I could get them to carry four things out of these 52 episodes, it's these.
1. Evaluate AI tools on verification, not generation. Every vendor demo shows the generation moment: the drafted email, the auto-built should-cost model, the instant quote summary. Almost no demo shows the checking moment, and the checking moment is where six months of evidence says the cost lives. The real test of a sourcing tool isn't whether it summarizes three quotes -- it's whether it catches that Quote A excludes tooling, Quote B assumes a different resin grade, Quote C used last year's volumes, and the lowest number carries a 14-week risk to your validation build. Evaluate by error modes, not fluency:
The demo question | The operating question | What to inspect |
|---|---|---|
Did it produce an answer? | Did the RFQ pack include the right drawing revision? | Completeness, source traceability, revision control |
Does the answer look right? | Is the should-cost consistent with supplier history and commodity movement? | Benchmarks, historical quotes, assumptions cited |
Is it impressive? | Can a buyer trace every normalized number back to the source bid? | Line-item lineage, flagged exceptions |
Do users like it? | Did cycle time, cost variance, or launch risk actually improve? | Measured before/after, not sentiment |
2. Instrument adoption; don't trust impressions. The METR result should be taped to the wall of every AI steering committee: smart, experienced people were 19% slower and believed they were 20% faster. Wharton's research found 94% of executives now use generative AI at least weekly; EY found only 36% of procurement organizations have meaningful implementations. The difference between using AI and benefiting from it is measurement. Pick the two or three numbers that matter -- sourcing cycle time, quote turnaround, cost variance at award -- and baseline them before the pilot, the way we laid out in the AI sourcing playbook.
3. Your data is the asset that compounds. Get it agent-ready. Gartner finds 74% of procurement leaders say their data isn't AI-ready, and a May 2026 Gartner survey found just 36% of CPOs are very confident they can redesign their function for AI at all. Meanwhile the builders are telling you the moat is exactly that data: structured quote history, clean BOMs, supplier records an agent can traverse. Most procurement systems were built assuming a human would be the integration layer -- the buyer who remembers that Rev C supersedes the Rev B still attached to the old email thread. That assumption holds at human speed and breaks at machine speed. Every quarter your sourcing history sits in inboxes and disconnected spreadsheets is a quarter of compounding you don't get back.
4. The friction is real -- which is exactly why it favors challengers. Andreessen is probably right that large incumbent organizations will absorb this slowly: committees, vetoes, licensed gatekeepers, the 95% of pilots that stall. If you're a challenger manufacturer, that institutional drag is your opening, the same way it was in sales AI before procurement AI. The MIT data says external partnerships succeed at roughly twice the rate of internal builds. Speed of organizational learning -- pilot, measure, correct -- is the variable you control.
This is the bet LightSource makes, for what it's worth. We build the direct-materials system where engineering, procurement, and supplier data live in one place: bids normalized on arrival so buyers verify instead of re-keying, quote and cost history structured so it's usable by the NPI team -- and by whatever model you point at it in three years. Customers like Amazon, BRP, and Shure use it to run sourcing cycles in weeks instead of months. The premise is the same one running through all 52 episodes: generation is getting cheap everywhere, so the durable advantages are verified data and fast feedback loops.
Six months in, the feed has made me more optimistic and more patient at the same time. More optimistic because the production numbers are real -- the people reporting 7x output aren't speculating, they're counting. More patient because every one of them earned it with unglamorous work: evals, lints, data plumbing, review systems. AI doesn't fix a weak process; it makes weak processes fail faster and strong processes compound. The frontier isn't a solved consensus being executed. It's a working argument -- about verification, measurement, and memory -- and that argument is the most useful product the AI industry ships. I'll keep listening.
Sources
METR: Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity -- the randomized controlled trial: 16 developers, 246 tasks, 19% slower with AI vs. a believed 20% speedup
OpenAI: Why SWE-bench Verified no longer measures frontier coding capabilities -- the February 2026 audit: 59.4% flawed tests and industry-wide contamination
Latent Space: The End of SWE-Bench Verified -- Mia Glaese and Olivia Watkins (OpenAI) on broken tests and contamination forensics
Latent Space: Extreme Harness Engineering for Token Billionaires -- Ryan Lopopolo (OpenAI) on running 1M LOC with zero human pre-merge review
Latent Space: Shopify's AI Phase Transition -- Mikhail Parakhin on 100% adoption, review-token ratios, and more bugs in total
Latent Space: The Age of Async Agents -- Walden Yan (Cognition) on 80% agent-written commits and the two-week quality cliff
Latent Space: Doing Vibe Physics -- Alex Lupsasca (OpenAI/Vanderbilt) on three-day derivations and three-week verification
Latent Space: Scaling Past Informal AI -- Carina Hong (Axiom Math) on the Lean compiler as the verifier of last resort
Latent Space: Satya Nadella at Microsoft Build -- private evals as IP, agent traces as assets, and AI's 12-18 month legitimacy window
Latent Space: Marc Andreessen on the Death of the Browser -- why structural cartels will throttle AI adoption
Latent Space: Every Agent Needs a Box -- Aaron Levie (Box) on context rot and documentation culture as moat
Latent Space: GitHub's Plan for Agents -- Kyle Daigle on commit growth and codifying trust
Latent Space: Reality: The Final Eval -- Andon Labs on benchmark noise floors and agents behaving badly in the real world
Latent Space: AIE Europe Debrief + Agent Labs -- swyx's coding-ARR estimates and the memory constraint
Fortune: MIT report finds 95% of generative AI pilots are failing -- the GenAI Divide study
Art of Procurement: State of AI in Procurement 2026 -- Wharton (94% weekly usage), Hackett (49% piloted / 4% scaled), and EY (36% meaningful implementations) figures
Gartner: 2025 Leadership Vision for Chief Procurement Officers -- 74% of procurement leaders say their data isn't AI-ready
Gartner: May 2026 CPO survey -- 36% of CPOs very confident in redesigning the function for AI
Latent Space podcast archive -- the full source feed, December 2025 through June 2026
Frequently Asked Questions
What is the Latent Space podcast?
Latent Space is a podcast and newsletter for AI engineers, hosted by swyx (Shawn Wang) and Alessio Fanelli. Guests are primarily the people building frontier AI: researchers at OpenAI, Google DeepMind, and Anthropic, plus founders and executives at companies like Shopify, GitHub, Box, Cursor, and Cognition. It's one of the highest-signal public records of how AI practitioners actually think, argue, and change their minds.
Why is verification considered the new bottleneck in AI?
Because models can now produce code, analysis, proofs, and documents far faster than humans or existing systems can check them. OpenAI retired its own standard coding benchmark after finding most of its hardest tests were flawed; physicists report spending three weeks verifying what an AI derives in three days; and Shopify's CTO notes that good models write fewer bugs per line but more bugs in total because volume grows faster than quality. Wherever generation gets cheap, the scarce resource becomes trusting the output.
Did the METR study prove AI tools don't work for developers?
No -- it proved perception is unreliable, and that the work system matters as much as the model. In METR's randomized controlled trial, experienced developers took 19% longer on tasks with AI assistance while believing they had been 20% faster. Organizations like Shopify and Cognition that built measurement and review infrastructure around the same class of tools report large, real output gains. The consistent lesson is to instrument AI adoption with hard metrics rather than self-reported speed.
What should procurement teams do before deploying AI agents?
Get the data layer ready first. Gartner finds 74% of procurement leaders say their data isn't AI-ready, and MIT's research shows 95% of enterprise gen-AI pilots fail to show measurable P&L impact -- usually for integration and data reasons, not model quality. That means consolidating quote history, BOMs, and supplier records into structured, retrievable form, then baselining metrics like sourcing cycle time so any pilot's effect is measurable against real numbers.
What is the biggest risk of using AI in direct materials sourcing?
Confident output built on incomplete or stale context. If supplier history, engineering exceptions, quote assumptions, and prior quality escapes aren't captured in structured form, an AI can produce a recommendation that reads well and fails in production -- the lowest quote that excluded tooling, or the supplier that has missed two launch ramps. The fix is the same discipline manufacturing applies to parts: first article inspection and process control for AI-generated decisions, not end-of-line inspection.
Is it too early or too late for manufacturers to adopt AI in procurement?
Neither, but the window favors fast learners. Adoption is nearly universal (Wharton found 94% of executives use generative AI weekly) while conversion is rare (Hackett found only 4% of procurement teams reached large-scale deployment). The gap between piloting and compounding comes from data readiness, verification infrastructure, and measurement -- all things a mid-sized challenger can build faster than a large incumbent can clear its own committees.
Since December I have listened to 52 episodes of the Latent Space podcast -- roughly six months of long-form conversations with the people actually building AI. Not the commentators: the builders. Jeff Dean. Satya Nadella. Shopify's CTO Mikhail Parakhin. GitHub's COO Kyle Daigle. The OpenAI researchers who run frontier evals, the founders renting computers to agents, the physicists pointing models at problems humans couldn't crack, the researchers watching autonomous agents lie to customers and form price cartels in simulated vending-machine businesses.
Any single episode is interesting. The corpus is something else entirely. Listen across all of them and you start to hear two things no individual guest says out loud: themes that recur in field after field until they look structural, and people at the top of the field flatly contradicting each other. The second category turns out to be more useful than the first. When everyone agrees, you've learned what's already priced in. When Marc Andreessen says AI adoption will be throttled for decades and Satya Nadella says the industry has 12 to 18 months to show up in GDP numbers, you've found the live question.
I run a company that builds AI software for manufacturers, so this feed is industry intelligence for me. But most of what I've learned isn't about my industry. It's about what happens when generation gets cheap in any domain -- code, proofs, quotes, plans -- and what the people furthest ahead are doing about it. Here is the compressed version: three themes, the contradictions inside each, and what I think procurement and engineering leaders at manufacturers should take from them.
Theme | The consensus | The live argument |
|---|---|---|
Verification | Checking AI output, not producing it, is now the scarce resource -- the same story in code, math, physics, and evals | Whether verification itself can be automated: OpenAI runs codebases with zero human pre-merge review, while Cognition measured a quality cliff after just two weeks of it |
Productivity | Adoption is real and accelerating: ~100% daily AI usage at Shopify, 80% of Cognition's own commits written by agents | Whether it nets out positive today: METR's controlled trial found developers 19% slower with AI while believing they were 20% faster |
Memory | Context, not model intelligence, is the binding constraint for real work | Whether it's an architecture problem the labs will solve or a data problem every company must solve for itself |
Benchmarks | Static benchmarks are dying; OpenAI retired SWE-bench Verified after finding most of its hardest tests were broken | What replaces them: private enterprise evals as "IP" (Nadella) vs. revenue-denominated reality tests (Andon Labs) |
Adoption speed | The technology is ready for more than organizations can absorb | Andreessen: licensed professions and institutional cartels will slow everything down. Nadella: show economic results fast or lose legitimacy |
Generation Got Cheap. Verification Became the Bottleneck.
The single clearest pattern across six months: the cost of producing output has collapsed, and the cost of trusting it has not. Every domain the podcast touched -- software, mathematics, physics, drug discovery, evaluation itself -- repeated the same arc.
Start with the benchmark story, because it's the cleanest. In February, OpenAI stopped reporting SWE-bench Verified scores, the industry-standard benchmark for AI coding agents. Their audit found that 59.4% of the hardest problems had flawed test cases -- tests that rejected correct solutions for not guessing an unstated function name -- and that every frontier model showed signs of training-data contamination. Olivia Watkins, who built the benchmark's verified set, put the asymmetry plainly on the February episode: passing a test means you probably did well; failing one doesn't mean you didn't. Read that again -- the output may be correct while the checker is wrong. The instrument for verifying AI coding skill was itself unverified. Models scoring above 80% dropped to roughly 23% on a successor benchmark built to resist contamination.
Then listen to the people running production systems. Ryan Lopopolo, a principal engineer at OpenAI, runs a one-million-line codebase with zero human pre-merge review -- not because verification stopped mattering, but because he rebuilt it as infrastructure: review agents, lints, tests, every engineering standard encoded as a written rule a machine can enforce. When an agent makes a mistake, the question isn't "who missed it" but "what written rule would have caught this." Shopify's Parakhin runs the same play from the opposite direction: his engineers get unlimited AI usage, and the metric he actually manages is the ratio of review tokens to generation tokens. His reasoning is the whole theme in one sentence: good models write fewer bugs per line but so much more code that you end up with more bugs in total. Volume defeats per-unit quality. GitHub's Daigle, staring at a platform that did about a billion commits in 2025 and is pacing toward 14 billion this year, describes the merge boundary the same way: "ultimately we're trying to codify trust."
The same inversion is happening in places with much higher proof standards than a web app. Alex Lupsasca, a Breakthrough Prize-winning physicist now at OpenAI, described getting a full AI-drafted paper on graviton amplitudes in about three days -- and then spending three weeks checking it. "A year ago, if you told me an AI would do really hard calculations and most of the human effort would go to verifying the answer, I'd have thought you were crazy," he said on the May episode. Carina Hong's company Axiom exists because there aren't enough expert mathematicians alive to grade frontier-level proofs, so she replaced the human judges with the Lean compiler: the proof compiles or it doesn't. Formal verification, a niche academic concern two years ago, is regaining value precisely because generation got cheap.
And here is the boundary condition that makes all of this concrete. Cognition -- the company behind Devin, which now writes around 80% of its own commits -- ran the experiment everyone wants to run: just let the agents merge their own work. The codebase hit a measurable quality cliff at roughly two weeks. One button's logic scattered across ten places, each subtly different. Walden Yan's team found that AI-native codebases "regress to your worst engineer," because the model amplifies whatever patterns it finds. Zero-human-review software development is real at OpenAI and fatal at two weeks without the guardrail infrastructure. The difference between those two outcomes is not the model. It's the verification system around it.
The Optimists and the Skeptics Are Both Holding Real Data
The adoption numbers coming through the feed are not hype. They are production metrics reported by the people accountable for them. Shopify crossed essentially 100% daily AI-tool usage company-wide after a December 2025 inflection, with merged pull requests growing about 30% month over month. Cognition went from 16% to 80% agent-written commits in one quarter, with PR volume up roughly 7x on 10% headcount growth. swyx estimates coding AI alone minted three multi-billion-dollar revenue lines in about a year -- roughly $2.5B at Anthropic, $2B at OpenAI, $2B at Cursor. Whatever discount you apply to ARR accounting, the direction is unambiguous.
Now the other column. METR ran a randomized controlled trial -- 16 experienced open-source developers, 246 real tasks on codebases they knew deeply. With AI tools, they took 19% longer. The detail that should keep every executive honest: the same developers estimated AI had made them 20% faster. The perception gap, not the slowdown, is the finding. Economists and ML experts had predicted 38-39% speedups. Everyone's intuition pointed the same direction, and the stopwatch disagreed.
The enterprise version of that gap is well documented. MIT's NANDA initiative found 95% of corporate gen-AI pilots deliver no measurable P&L impact. In procurement specifically, the Hackett Group found 49% of teams piloted generative AI in 2024 -- and 4% reached large-scale deployment. Adoption is nearly universal; conversion is rare. We've written before about cutting through analyst claims on AI in procurement, and the gap has only widened since.
The structural skeptics go further. Marc Andreessen's argument is that both the utopians and the doomers are too optimistic, because the constraint isn't capability -- it's that a large share of the economy sits behind occupational licensing, union contracts, and government monopolies that will resist absorption for decades. Nadella, sitting inside the largest enterprise software franchise on earth, draws the opposite deadline from the same worry: "the world is going to be very skeptical of tech companies that say trust us" -- the industry needs AI visible in economic growth within 12 to 18 months, not in keynote demos.
Here's how I reconcile the two columns: Shopify and METR are not measuring the same thing. They are measuring different work systems. Shopify's numbers come from an organization that spent a year building review infrastructure, instrumented everything, and manages a token ratio on a dashboard. METR's developers were capable people with capable models dropped into work that had none of that scaffolding. The model is not the only variable -- the work surface decides whether the tool compounds. And the perception trap catches both: METR's developers felt 20% faster while being 19% slower, which is why Brex's CTO rejects "% of code written by AI" as a metric and why the companies pulling ahead measure AI like any other operation. If your AI pilot is a generic assistant bolted onto disconnected ERP exports, stale supplier masters, and PDFs in email threads, don't expect Shopify results. You've recreated the METR condition.
Perception vs. the stopwatch -- Source: METR randomized controlled trial, 16 experienced developers, 246 tasks (July 2025).
Memory, Not Intelligence, Is the Wall
Ask the builders what actually blocks enterprise deployment and almost none of them say model capability. swyx's framing stuck with me: context length is the slowest-scaling axis in AI -- million-token windows have existed for two years and almost nobody uses them well. Memory, not intelligence, is the binding constraint.
Aaron Levie, whose company sits on the unstructured documents of most of the Fortune 500, sharpened it: the problem is context rot, not context length. A knowledge worker's relevant corpus might be 50 million pages; a model reliably reasons over tens of thousands of tokens. The real work is search, metadata, permissions, and knowing when to stop -- unglamorous data plumbing, not intelligence. Cognition's Yan added the twist I find most interesting: memory generation is harder than memory retrieval. About 95% of the useful memories Devin accumulates come from user corrections -- the system learns where humans push back. And Cursor's Ashvin Nair, who spent two years on OpenAI's reasoning team, thinks continual learning -- experience written back into the model -- is what comes next, currently blocked by inference infrastructure that treats every session as stateless.
Translate memory generation into sourcing and you'll recognize it immediately. A buyer knows a supplier missed its last PPAP date because the plating subcontractor was overloaded. An engineer knows another supplier quotes aggressively and then comes back with DFM exceptions. A quality manager knows a casting vendor is fine for prototypes but struggles below a certain wall thickness. That knowledge lives in email threads, meeting notes, and people's heads -- so when the next sourcing event starts, the organization learns the same lesson again, at full price. A model pointed at that corpus isn't reasoning over institutional memory. It's reading a landfill, confidently.
The contradiction here is between the labs and everyone else. Jeff Dean is fairly relaxed about it: hierarchical retrieval will eventually let models "attend to a trillion tokens", making it an engineering problem. Maybe. But every operator on the feed is acting as if the durable asset is on their side of the API: Nadella wants enterprise agent traces treated as a balance-sheet asset and calls a company's private evals "maybe one of the biggest drivers of IP." Levie argues documentation culture becomes a compounding moat, because agents can't compensate for institutional knowledge that lives in people's heads. Shopify's customer-behavior simulator is credible only because it's grounded in decades of proprietary A/B test history -- Parakhin's own assessment of why it can't be copied is simply: who else has that data?
Whichever way the architecture goes, the strategic conclusion is identical: the scarce input is your organization's structured, retrievable context. That's why we keep telling manufacturers to consolidate their data, not their software. The model your team uses in 2028 will not be the one you use today. The record of every quote, every spec revision, every supplier correction -- that compounds across model generations, the same way Devin's user-correction memories do.
What Manufacturing Already Knows About This
Here's what struck me somewhere around episode 40: the software industry is speed-running a curriculum manufacturing finished a century ago.
When generation got cheap on the factory floor -- when interchangeable parts and the moving line made volume the easy part -- quality didn't take care of itself. Volume defeated per-unit quality, exactly as Parakhin describes in code. The answers the industry converged on are the ones the AI world is now reinventing with new names. Statistical process control is Shopify's token-ratio dashboard: don't inspect every unit, instrument the process. First article inspection and PPAP are the planning gate before a long autonomous run: verify intensively at the start, before volume multiplies the error. Incoming quality control is the review agent at the merge boundary. Toyota's jidoka -- machines that stop themselves when something is wrong, so humans inspect by exception -- is precisely Lopopolo's "what written rule would have caught this" loop. Even the SWE-bench collapse has a factory name: measurement system analysis. Before you trust the data, you qualify the gauge -- and the AI industry just discovered its most-cited gauge couldn't pass the audit.
I spent years at Tesla and Waymo watching both halves of this lesson. (Applied Intuition's Qasar Younis put a line on the feed I'd have appreciated back then: Waymo is interesting for a long time but not worth $126 billion -- until it is. Compounding systems look like nothing happening, then a step change.) The half that matters here: nobody in manufacturing believes you can inspect quality into a product at the end of the line. Quality is designed into the process or it doesn't exist. The AI industry's verification crisis is the discovery that the same is true for intelligence.
That's also why I'd gently push back on anyone in our industry who treats this AI moment as unprecedented. The technology is new. The operations problem -- cheap generation, scarce verification -- is the oldest problem manufacturing has.
The adoption-to-scale gap in procurement -- Sources: AI at Wharton (2025), The Hackett Group 2025 CPO Agenda, EY Global CPO Survey via Art of Procurement.
What I Want Our Customers to Internalize
Most of our customers are procurement and engineering leaders at manufacturers competing on speed -- the people whose jobs the AI-risk rankings keep putting in the crosshairs. If I could get them to carry four things out of these 52 episodes, it's these.
1. Evaluate AI tools on verification, not generation. Every vendor demo shows the generation moment: the drafted email, the auto-built should-cost model, the instant quote summary. Almost no demo shows the checking moment, and the checking moment is where six months of evidence says the cost lives. The real test of a sourcing tool isn't whether it summarizes three quotes -- it's whether it catches that Quote A excludes tooling, Quote B assumes a different resin grade, Quote C used last year's volumes, and the lowest number carries a 14-week risk to your validation build. Evaluate by error modes, not fluency:
The demo question | The operating question | What to inspect |
|---|---|---|
Did it produce an answer? | Did the RFQ pack include the right drawing revision? | Completeness, source traceability, revision control |
Does the answer look right? | Is the should-cost consistent with supplier history and commodity movement? | Benchmarks, historical quotes, assumptions cited |
Is it impressive? | Can a buyer trace every normalized number back to the source bid? | Line-item lineage, flagged exceptions |
Do users like it? | Did cycle time, cost variance, or launch risk actually improve? | Measured before/after, not sentiment |
2. Instrument adoption; don't trust impressions. The METR result should be taped to the wall of every AI steering committee: smart, experienced people were 19% slower and believed they were 20% faster. Wharton's research found 94% of executives now use generative AI at least weekly; EY found only 36% of procurement organizations have meaningful implementations. The difference between using AI and benefiting from it is measurement. Pick the two or three numbers that matter -- sourcing cycle time, quote turnaround, cost variance at award -- and baseline them before the pilot, the way we laid out in the AI sourcing playbook.
3. Your data is the asset that compounds. Get it agent-ready. Gartner finds 74% of procurement leaders say their data isn't AI-ready, and a May 2026 Gartner survey found just 36% of CPOs are very confident they can redesign their function for AI at all. Meanwhile the builders are telling you the moat is exactly that data: structured quote history, clean BOMs, supplier records an agent can traverse. Most procurement systems were built assuming a human would be the integration layer -- the buyer who remembers that Rev C supersedes the Rev B still attached to the old email thread. That assumption holds at human speed and breaks at machine speed. Every quarter your sourcing history sits in inboxes and disconnected spreadsheets is a quarter of compounding you don't get back.
4. The friction is real -- which is exactly why it favors challengers. Andreessen is probably right that large incumbent organizations will absorb this slowly: committees, vetoes, licensed gatekeepers, the 95% of pilots that stall. If you're a challenger manufacturer, that institutional drag is your opening, the same way it was in sales AI before procurement AI. The MIT data says external partnerships succeed at roughly twice the rate of internal builds. Speed of organizational learning -- pilot, measure, correct -- is the variable you control.
This is the bet LightSource makes, for what it's worth. We build the direct-materials system where engineering, procurement, and supplier data live in one place: bids normalized on arrival so buyers verify instead of re-keying, quote and cost history structured so it's usable by the NPI team -- and by whatever model you point at it in three years. Customers like Amazon, BRP, and Shure use it to run sourcing cycles in weeks instead of months. The premise is the same one running through all 52 episodes: generation is getting cheap everywhere, so the durable advantages are verified data and fast feedback loops.
Six months in, the feed has made me more optimistic and more patient at the same time. More optimistic because the production numbers are real -- the people reporting 7x output aren't speculating, they're counting. More patient because every one of them earned it with unglamorous work: evals, lints, data plumbing, review systems. AI doesn't fix a weak process; it makes weak processes fail faster and strong processes compound. The frontier isn't a solved consensus being executed. It's a working argument -- about verification, measurement, and memory -- and that argument is the most useful product the AI industry ships. I'll keep listening.
Sources
METR: Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity -- the randomized controlled trial: 16 developers, 246 tasks, 19% slower with AI vs. a believed 20% speedup
OpenAI: Why SWE-bench Verified no longer measures frontier coding capabilities -- the February 2026 audit: 59.4% flawed tests and industry-wide contamination
Latent Space: The End of SWE-Bench Verified -- Mia Glaese and Olivia Watkins (OpenAI) on broken tests and contamination forensics
Latent Space: Extreme Harness Engineering for Token Billionaires -- Ryan Lopopolo (OpenAI) on running 1M LOC with zero human pre-merge review
Latent Space: Shopify's AI Phase Transition -- Mikhail Parakhin on 100% adoption, review-token ratios, and more bugs in total
Latent Space: The Age of Async Agents -- Walden Yan (Cognition) on 80% agent-written commits and the two-week quality cliff
Latent Space: Doing Vibe Physics -- Alex Lupsasca (OpenAI/Vanderbilt) on three-day derivations and three-week verification
Latent Space: Scaling Past Informal AI -- Carina Hong (Axiom Math) on the Lean compiler as the verifier of last resort
Latent Space: Satya Nadella at Microsoft Build -- private evals as IP, agent traces as assets, and AI's 12-18 month legitimacy window
Latent Space: Marc Andreessen on the Death of the Browser -- why structural cartels will throttle AI adoption
Latent Space: Every Agent Needs a Box -- Aaron Levie (Box) on context rot and documentation culture as moat
Latent Space: GitHub's Plan for Agents -- Kyle Daigle on commit growth and codifying trust
Latent Space: Reality: The Final Eval -- Andon Labs on benchmark noise floors and agents behaving badly in the real world
Latent Space: AIE Europe Debrief + Agent Labs -- swyx's coding-ARR estimates and the memory constraint
Fortune: MIT report finds 95% of generative AI pilots are failing -- the GenAI Divide study
Art of Procurement: State of AI in Procurement 2026 -- Wharton (94% weekly usage), Hackett (49% piloted / 4% scaled), and EY (36% meaningful implementations) figures
Gartner: 2025 Leadership Vision for Chief Procurement Officers -- 74% of procurement leaders say their data isn't AI-ready
Gartner: May 2026 CPO survey -- 36% of CPOs very confident in redesigning the function for AI
Latent Space podcast archive -- the full source feed, December 2025 through June 2026
Frequently Asked Questions
What is the Latent Space podcast?
Latent Space is a podcast and newsletter for AI engineers, hosted by swyx (Shawn Wang) and Alessio Fanelli. Guests are primarily the people building frontier AI: researchers at OpenAI, Google DeepMind, and Anthropic, plus founders and executives at companies like Shopify, GitHub, Box, Cursor, and Cognition. It's one of the highest-signal public records of how AI practitioners actually think, argue, and change their minds.
Why is verification considered the new bottleneck in AI?
Because models can now produce code, analysis, proofs, and documents far faster than humans or existing systems can check them. OpenAI retired its own standard coding benchmark after finding most of its hardest tests were flawed; physicists report spending three weeks verifying what an AI derives in three days; and Shopify's CTO notes that good models write fewer bugs per line but more bugs in total because volume grows faster than quality. Wherever generation gets cheap, the scarce resource becomes trusting the output.
Did the METR study prove AI tools don't work for developers?
No -- it proved perception is unreliable, and that the work system matters as much as the model. In METR's randomized controlled trial, experienced developers took 19% longer on tasks with AI assistance while believing they had been 20% faster. Organizations like Shopify and Cognition that built measurement and review infrastructure around the same class of tools report large, real output gains. The consistent lesson is to instrument AI adoption with hard metrics rather than self-reported speed.
What should procurement teams do before deploying AI agents?
Get the data layer ready first. Gartner finds 74% of procurement leaders say their data isn't AI-ready, and MIT's research shows 95% of enterprise gen-AI pilots fail to show measurable P&L impact -- usually for integration and data reasons, not model quality. That means consolidating quote history, BOMs, and supplier records into structured, retrievable form, then baselining metrics like sourcing cycle time so any pilot's effect is measurable against real numbers.
What is the biggest risk of using AI in direct materials sourcing?
Confident output built on incomplete or stale context. If supplier history, engineering exceptions, quote assumptions, and prior quality escapes aren't captured in structured form, an AI can produce a recommendation that reads well and fails in production -- the lowest quote that excluded tooling, or the supplier that has missed two launch ramps. The fix is the same discipline manufacturing applies to parts: first article inspection and process control for AI-generated decisions, not end-of-line inspection.
Is it too early or too late for manufacturers to adopt AI in procurement?
Neither, but the window favors fast learners. Adoption is nearly universal (Wharton found 94% of executives use generative AI weekly) while conversion is rare (Hackett found only 4% of procurement teams reached large-scale deployment). The gap between piloting and compounding comes from data readiness, verification infrastructure, and measurement -- all things a mid-sized challenger can build faster than a large incumbent can clear its own committees.



Faster sourcing. Lower cost. Less chaos.
See how LightSource connects engineering, procurement, and suppliers in one operating system to help you launch faster at lower cost.
SOC 2
Kearney #1 2024
Gartner Cool Vendor
Procuretech 100
G2 Top Rated
Faster sourcing. Lower cost. Less chaos.
See how LightSource connects engineering, procurement, and suppliers in one operating system to help you launch faster at lower cost.
SOC 2
Kearney #1 2024
Gartner Cool Vendor
Procuretech 100
G2 Top Rated
Faster sourcing. Lower cost. Less chaos.
See how LightSource connects engineering, procurement, and suppliers in one operating system to help you launch faster at lower cost.
SOC 2
Kearney #1 2024
Gartner Cool Vendor
Procuretech 100
G2 Top Rated
Trusted by:
Trusted by:
Trusted by:
*GARTNER is a registered trademark and service mark of Gartner, Inc. and/or its affiliates in the U.S. and internationally, and COOL VENDORS is a registered trademark of Gartner, Inc. and/or its affiliates and are used herein with permission. All rights reserved. Gartner does not endorse any vendor, product or service depicted in its research publications, and does not advise technology users to select only those vendors with the highest ratings or other designation. Gartner research publications consist of the opinions of Gartner’s research organization and should not be construed as statements of fact. Gartner disclaims all warranties, expressed or implied, with respect to this research, including any warranties of merchantability or fitness for a particular purpose.